
こんにちは!KCompanyの八木です。
OpenAI APIのリファレンス入門シリーズ第二弾です!
前回と同様に、基本的に本家のドキュメントや本家のAPIリファレンスの内容にそってやってみた(内容をまとめてみた)、という内容になります。開発環境や設定などについては、第一回目を参照ください!
二回目の今日はテキスト生成(Text generation)、要するにチャットをやっていきます!
それではっそくいってみましょう!
テキスト生成モデル
テキスト生成モデルの概要
テキスト生成モデルは、いわゆる大規模言語モデルといわれるものです。OpenAIのテキスト生成モデルは自然言語やコード、画像などを理解できるようにトレーニングされています。このモデルは、何か入力を与えてあげることで、出力結果を得ることができます。入力の部分がいわゆる「プロンプト」です。プロンプトを「プログラミング」し適切な指示を与えることで、難しいタスクをこなしてくれるようになるわけです。
このブログを読んでいる方であれば既に想像が及んでいたり実際にご利用されたことがあるとは思いますが、テキスト生成モデルを使うことで、ドキュメント草稿の作成や、コードの作成、ナレッジに裏打ちされた回答の作成、テキストの分析、ソフトウェアへの自然言語インタフェースの提供、様々なトピックでのチュータリング、言語翻訳、ゲーム用のキャラクターシミュレーションといったことができるようになります。Visionを用いることで、テキストと画像を一緒に使って対話をすることも可能です。
テキスト生成モデルを使うには
テキスト生成モデルをAPIとして利用するには、Chat Completions API にリクエストを送信すればOKです。Chat Completions API にリクエストを送信する際には、第1回でもお伝えしたAPI Keyとインプット(プロンプト)をリクエストに含めれば大丈夫です。その結果、出力をレスポンスとして受け取るという流れになります。
テキスト生成モデルには、最近発表されたgpt-4oからクラッシクなgpt-3.5-turboまで様々なモデルがあります。APIに実装する前にOpenAIの管理画面のPlayGroundで現在提供されている様々なモデルを試すことができます。
Chat Completions API
以下がChat Completions APIにリクエストを送るNode.jsのサンプルコードです。チャットにすると、当然のことながら、ユーザーとシステム(AI)で複数回のやりとりが発生しますが、このやりとりをいい感じにとりまとめしてくれるように設計されています。
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const completion = await openai.chat.completions.create({
messages: [{"role": "system", "content": "あなたは優秀なアシスタントです"},
{"role": "user", "content": "FIFAワールドカップ2022の日本代表の成績を教えて"},
{"role": "assistant", "content": "ベスト8入りを目指したラウンド16でクロアチアに延長とPK戦の末に惜しくも敗れました。"},
{"role": "user", "content": "どこで開催されましたか?"}],
model: "gpt-3.5-turbo",
});
console.log(completion.choices[0]);
}
main();重要なポイントとしては、messeagesパラメーターの理解になります。メッセージは、コード内にあるように以下の2つを持つオブジェクトの配列である必要があります。
- role(“system”、”user”、”assistant”のいずれか)
- sysytem: アシスタントの振る舞いを設定します。例えば、アシスタントの性格を変更したり、会話全体を通して従うべき具体的な指示を与えたりできます。ただし、systemは省略可能で、”あなたは優秀なアシスタントです”などの一般的なメッセージを使用した場合と、モデルの振る舞いはおおむね同じになる可能性があることに注意してください。
- user: ユーザーが作成したメッセージ(とみなされます)。アシスタントに対する要求やコメントが含まれます。
- assistant: アシスタント(AI/システム)が作成したメッセージ(とみなされます)。ここには前のアシスタントの応答が格納されますが、あなた自身が望ましい振る舞いの例を書くこともできます。(上のサンプルコード内の記述がこれに該当します)。
- content
- 各roleからのメッセージが格納されます。
通常、会話はsystemメッセージから始まり、それに続いてユーザーとアシスタントのメッセージが交互に続きます。
なお、先程のコードに対するレスポンスは以下の通りです。
{
index: 0,
message: {
role: 'assistant',
content: '2022 FIFAワールドカップは、カタールで開催されました。この大会は、FIFAワールドカップ史上初めて11月から12月に開催された大会でもあります。'
},
logprobs: null,
finish_reason: 'stop'
}上記のレスポンスの結果からもわかるように、会話履歴を含めることは、ユーザーの指示が以前のメッセージを参照する場合に重要です。上の例では、ユーザーの最後の質問”どこで開催されましたか?”は、2022年のワールドカップについての以前のメッセージの文脈があってはじめて意味があります。モデルには過去のリクエストを記憶する機能がないため、各リクエストで関連するすべての情報を会話履歴の一部として提供する必要があります。会話がモデルのトークン制限に収まらない場合は、何らかの方法で短縮する必要があります。
Chat Completions responseのフォーマット
Chat Completions APIのレスポンスは以下のような結果で返却されます。
{
id: 'chatcmpl-9RbWijarRKgPqDqcfLSt5yuQgAfWV',
object: 'chat.completion',
created: 1716366136,
model: 'gpt-3.5-turbo-0125',
choices: [
{
index: 0,
message: [Object],
logprobs: null,
finish_reason: 'stop'
}
],
usage: { prompt_tokens: 115, completion_tokens: 59, total_tokens: 174 },
system_fingerprint: null
}メッセージだけ抜き出すときは以下のようにすればOKです。
completion.choices[0].message.contentJSONモード
Chat Completionsを利用する場合、JSONオブジェクトを利用することが一般的です。しかし、モデルから無効なJSONオブジェクトが出力される場合があります。
このエラーを防ぐために、response_formatを{ "type": "json_object" }に設定しましょう。こうすることでJSONモードを有効にでき、有効なJSONオブジェクトとしてパースできる文字列のみを生成するように制限されます。この設定は、gpt-4o, gpt-4-turbo, or gpt-3.5-turboを利用する場合は、やっておいて損はありません。
以下、重要な注意点です。
- JSONモードを使用する場合は、常にJSONを生成するようにモデルに指示をしてください。JSONを生成する明示的な指示がない場合、無限ループが発生し、トークン制限に達するまで実行される可能性があります。指示忘れ防止のために、APIは、文字列
"JSON"がコンテキストのどこかに現れない場合、エラーを発生させます。 - Chat Completions APIのレスポンスで
finish_reasonがlengthの場合、メッセージが切り捨てられた可能性があります。lengthとなるのは、生成がmax_tokensを超過したか、会話がトークン上限に達したかという可能性が考えられます。いずれにせよ、レスポンスをパースする前に、finish_reasonをチェックするようにしましょう。 - JSONモードは出力が特定のスキーマに一致することを保証するものではありません。ただし、エラーなくパースできる有効な出力であることを保証します。
- JSONモードは、function callingの一部として引数を生成する場合は常に有効になります。
JSONモードにおけるサンプルコードは以下の通りです。”あなたはJSON出力するためにデザインされた優秀なアシスタントです。”という風にインプットにJSONという文字列を入れないとエラーになります。
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const completion = await openai.chat.completions.create({
messages: [
{
role: "system",
content: "あなたはJSON出力するためにデザインされた優秀なアシスタントです。",
},
{ role: "user", content: "2022年ワールドカップで優勝した国は?" },
],
model: "gpt-4o",
response_format: { type: "json_object" },
});
console.log(completion.choices[0].message.content);
}
main();出力結果は以下のとおりです。
{
"year": 2022,
"tournament": "ワールドカップ",
"winner": "アルゼンチン"
}余談ですが、gpt-3.5-turbo-0125を利用すると、フランスが優勝という結果が返ってきたので、このサンプルではgpt-4oを利用しています。
アウトプットを再現可能にする(Reproducible outputs)
ChatGPTを使っている方であれば実感して頂けると思いますが、Chat Completionsは同じ入力(インプット)を与えても、出力(アウトプット)は異なる結果が返ってくることがしばしばあります。文章作成などは顕著ですね。
一方で、同じインプットであれば可能な限り同じようなアウトプットにしたいというニーズはあるかと思います。これを可能にするのが、seedとsystem_fingerprintです。
という存在になります。
APIを使って、ほぼ同じアウトプットを受け取るには、大まかに以下の2点が必要です。
- seedパラメーターに任意の整数値を指定し、同じアウトプットを得たいAPIリクエストでseedを使い回す
- seed以外の全てのパラメーターもリクエスト間で同じにする。promptやtempretureを同じにするという意味です。
seedについて
seedはChat Completion APIへリクエストするリクエストボディに付与できるパラメーターの一つです。同じ整数値を異なるリクエスト間で使うことで、同じような結果が返ってくることを期待できます。これは、繰り返しリクエストを送ることで、同じような結果が返ってくるようにいい感じに調整してくれるということです。もちろん、確実に同じ結果が返ってくるとことは保証されません。
system_fingerprintについて
APIへのリクエストの結果は、OpenAI社によるアップデートの影響をうける可能性があります。これを追跡可能にするのがsystem_fingerprintです。seedリクエストパラメーターとあわせて使用することで、アウトプットの結果のゆらぎをバックエンドの変更があった影響なのかどうかなどを把握することが、より容易になるというわけです。
実際にやってみる
以下ではHow to make your completions outputs consistent with the new seed parameterを参考に「お盆の過ごし方」というお題で短いエッセーを生成してみます。seedなしとありで比較するものになります。
以下はChatのレスポンスを受けるためのgetChatResponse関数です。システムメッセージとユーザーリクエストの他、seed値とtempratureも引数として設定できるようになっています。
import OpenAI from "openai";
const openai = new OpenAI();
const GPT_MODEL = "gpt-3.5-turbo-1106";
async function getChatResponse(systemMessage, userRequest, seed = null, temperature = 0.7) {
try {
const messages = [
{role: "system", content: systemMessage},
{role: "user", content: userRequest},
];
const response = await openai.chat.completions.create({
model: GPT_MODEL,
messages: messages,
seed: seed,
max_tokens: 200,
temperature: temperature,
});
const responseContent = response.choices[0].message.content;
const systemFingerprint = response.system_fingerprint;
const promptTokens = response.usage.prompt_tokens;
const completionTokens = response.usage.total_tokens - response.usage.prompt_tokens;
console.log(`Response: ${responseContent}`);
console.log(`System Fingerprint: ${systemFingerprint}`);
console.log(`Number of prompt tokens: ${promptTokens}`);
console.log(`Number of completion tokens: ${completionTokens}`);
return responseContent;
} catch (e) {
console.error(`An error occurred: ${e}`);
return null;
}
}まずはseed値なしの結果を出力してみましょう。
const topic = "お盆の時期の過ごし方";
const systemMessage = "あなたは優秀なアシスタントです";
const userRequest = `${topic}について、短いエッセイを生成してください。`;
async function getResponses() {
const responses = [];
for (let i = 0; i < 5; i++) {
console.log(`Output ${i + 1}n${"-".repeat(10)}`);
const response = await getChatResponse(systemMessage, userRequest);
responses.push(response);
}
return responses;
}
getResponses().then(responses => {
console.log(responses);
});以下が実際にコンソールに出力された結果になります。トピックの内容の範囲であり似たような内容であるものの、それぞれが異なる文章になっています。
レスポンス1
お盆の時期は、日本では家族や親せきとの再会や故人を供養するための大切な時期です。多くの人々は、この時期を家族と過ごすために故郷に帰省します。家族が一堂に集まり、お盆の行事や伝統的な食事を楽しみます。また、お墓参りや供物を捧げることもお盆の重要な行事の一つです。
お盆の時期には、地域ごとにさまざまな風習や行事があります。たとえば、盆踊りや盆遊び、盆栽展示な
レスポンス2
お盆の時期は、日本の伝統的なお盆祭りや行事が行われる大切な時期です。この時期には、家族や親せきが集まり、先祖を供養し、感謝の気持ちを表すためにさまざまな活動が行われます。
まず、お盆の時期には、家族が集まってお墓参りを行います。先祖の墓をきれいに掃除し、花や供物を捧げて、故人を偲びます。この時期には、家族が一堂に集まることで、親睦を深める貴重な機会となり
レスポンス3
お盆の時期は、日本の伝統的な行事であり、家族や親類と共に過ごす大切な時期です。お盆の時期には、先祖を追悼し、感謝の気持ちを表すために、様々な行事や習慣があります。
まず、お盆の時期には、先祖の霊を迎えるために家や墓地をきれいに掃除し、お供え物を用意します。これは、先祖に感謝の気持ちを示すとともに、彼らの霊を迎え入れる準備を整えるための行事です
レスポンス4
お盆の時期は日本の伝統的な祝日であり、家族や親戚が集まって親しい時間を過ごす特別な時期です。お盆の時期には、家族と共に亡くなった先祖を追悼し、感謝の気持ちを表すためにお墓参りを行うことが一般的です。
また、お盆の時期には、盆踊りや花火大会などの伝統的な行事が行われることもあります。これらの行事に参加することで、地域の伝統や文化を体験することができます。
さらに、お
レスポンス5
お盆の時期は、日本では家族や親せきが一堂に会する特別な時期です。多くの人々がこの期間を利用して、故郷に帰省したり、親戚や友人と再会したりします。お盆の過ごし方は、地域や家庭によって異なりますが、一般的には以下のような過ごし方があります。
まず、帰省したり、親戚や友人を招いたりして、家族での団欒を楽しむことが多いです。家族全員で集まって食事を囲んだり、昔話をしたり、親せき同士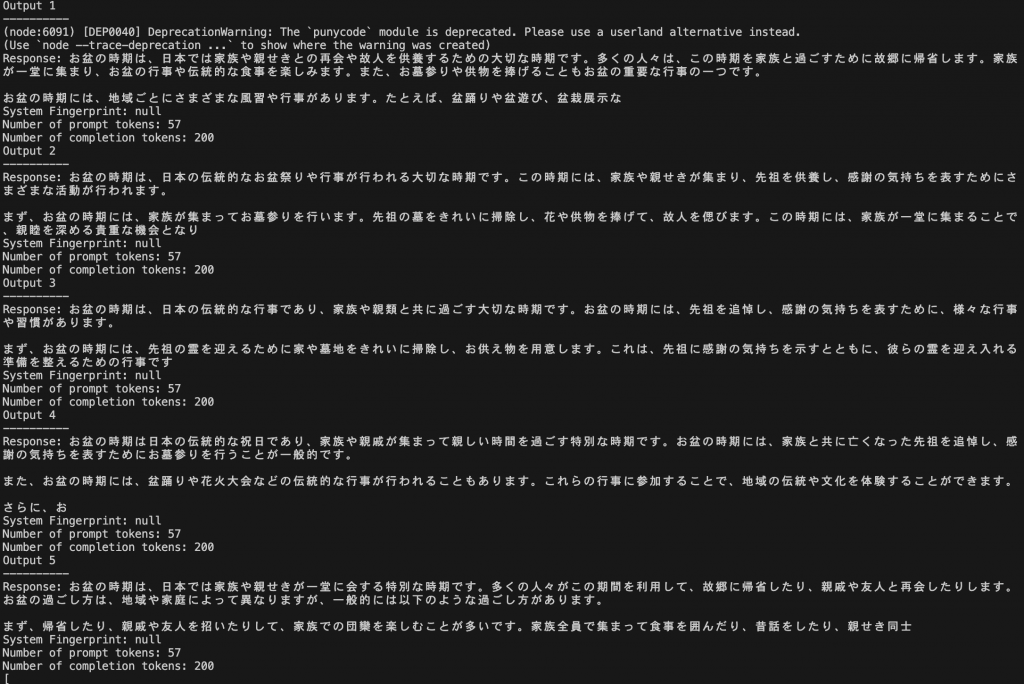
次にseed値を設定し、またtemparatureを0に設定した結果を出力してみましょう。
async function getResponsesWithSeed() {
const responses = [];
const SEED = 1234567;
for (let i = 0; i < 5; i++) {
console.log(`Output ${i + 1}n${"-".repeat(10)}`);
const response = await getChatResponse(systemMessage, userRequest, SEED, 0);
responses.push(response);
}
return responses;
}
getResponsesWithSeed().then(responses => {
console.log(responses);
});以下が実際にコンソールに出力された結果になります。seed値なしの結果と比べて、特に前半部分はほぼ同じ出力結果になっています。
レスポンス1
お盆の時期は日本の伝統的な行事であり、家族や親せきと共に過ごす大切な時期です。多くの人々はこの時期に故郷に帰り、先祖の墓を訪れて供養を行います。また、お盆の期間中は盆踊りやお盆料理を楽しむ機会も多く、地域ごとに様々な風習や行事が行われます。
お盆の時期を過ごす際に大切なことは、家族や親せきとの絆を深めることです。家族と一緒に帰省し、先
レスポンス2
お盆の時期は、日本の伝統的な行事であり、家族や親せきが集まって亡くなった先祖を供養し、感謝の気持ちを表す大切な時期です。多くの人々はこの時期に故郷に帰り、家族と共に過ごすことが多いです。
お盆の時期の過ごし方は、家族と共に亡くなった先祖を供養することが中心です。墓参りや仏壇の前で手を合わせることで、先祖への感謝や思い出を共有し、家族の絆を深めることがで
レスポンス3
お盆の時期は、日本の伝統的な行事であり、家族や親せきが集まって亡くなった先祖を供養し、感謝の気持ちを表す大切な時期です。多くの人々はこの時期に故郷に帰り、家族と共に過ごすことが多いです。お盆の時期には、様々な活動や行事が行われます。例えば、盆踊りや花火大会などの伝統的な行事が行われる地域もあります。
家族や親せきとの再会や交流を楽しむだけでなく、お盆の時
レスポンス4
お盆の時期は、日本の伝統的な行事であり、家族や親せきが集まって亡くなった先祖を供養し、感謝の気持ちを表す大切な時期です。多くの人々はこの時期に故郷に帰り、家族と共に過ごすことが多いです。お盆の時期には、様々な活動や行事が行われます。例えば、盆踊りやお墓参り、供物を捧げるなどがあります。
家族や親せきとの再会は、お盆の時期の最も楽しい部分の一つです。遠くに住
レスポンス5
お盆の時期は、日本の伝統的な行事であり、家族や親せきが集まって亡くなった先祖を供養し、感謝の気持ちを表す大切な時期です。多くの人々はこの時期に故郷に帰り、家族と共に過ごすことが多いです。お盆の時期には、様々な活動や行事が行われます。例えば、盆踊りや花火大会などのイベントが開催され、地域の人々が一堂に集まって楽しい時間を過ごします。
また、お盆の時期には、先祖の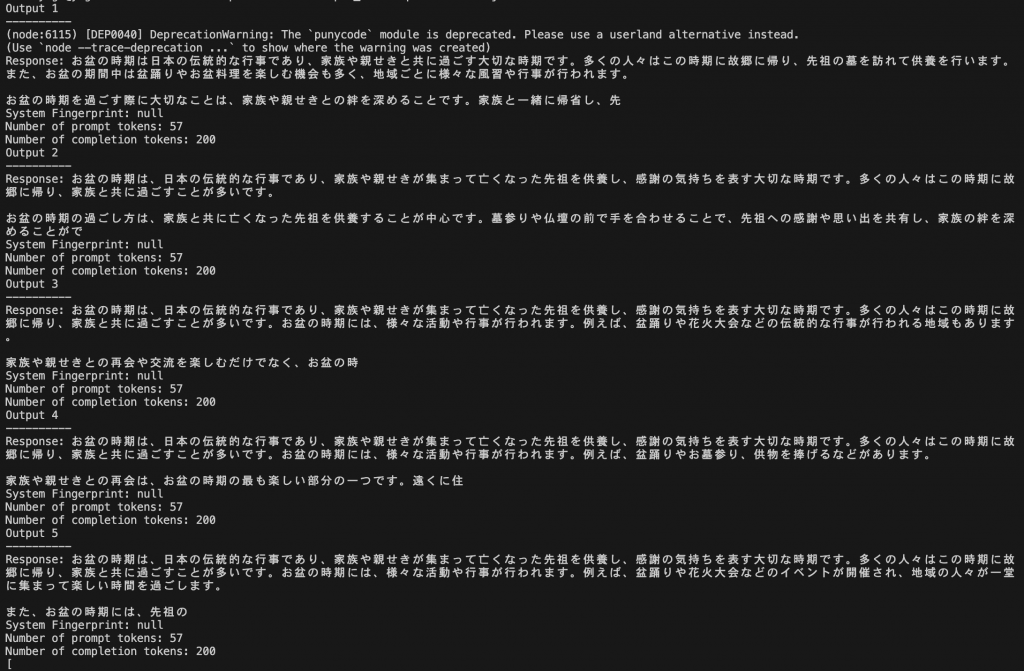
以上のように固定の整数seed値を使うことで、モデルから一貫した出力を生成することができるようになります。再現性が重要な回答を得たい場合に役立ちそうです。ただ、上記をみてわかるようにseed値は一貫性を確保するものの、出力する質自体を保証するものではないようです。
トークン管理
トークンとは
ChatGPTを始めとしたLLMではテキストをトークンと呼ばれる単位で読み書きしています。英語ですとtokenは1文字(a)から1単語まで(apple)幅があります。言語によりトークンは1文字より短いものから1単語より長いものまで幅があります。
日本語におけるトークン
気になるのは日本語のトークンが英語に比べてどの程度か?というこちらのブログによれば、GPT-4ですと日本語のトークンは英語に比べて2倍消費するような状況のようです。
トークン数がAPIコールに与える影響
トークン数がAPIコールに与える影響は主に以下の3つです。
- API使用時の料金はトークン量に比例する
- APIから結果が返ってくる時間はトークン量に比例する
- APIコールが正常に稼働していても、トークンの使える上限はモデルごとの上限になる(例えばgpt-3.5-turboなら4097トークン)
トークン数の考え方
トークンのトータル数はインプットとアウトプットの合計になります。API呼び出し時に10トークン消費して、20トークンの結果をもらったら、30トークン使用したということになります。モデルによりトークンあたりの単価が変わる点には注意しましょう。
トークンがどのくらい使用されているかは、APIレスポンスのオブジェクト内にresponse[’usage]や[’total_tokens’]の値があるので、それらを活用するとよいさそうです。
もしトークン数がモデルの上限値を超える場合は、例えばインプットのプロンプトの文章量(トークン数)を削減するなどの工夫が必要になります。
また、あまりにも長い会話をしていると、期待した結果が得られない場合があります。例えば、gpt-3.5-turboの場合、4090トークンの会話のあとは、わずか6トークンで会話が打ち切られてしまいます(上限が4097トークンのため)。
パラメーターの詳細
frequency_penaltyとpresence_penalty
公式ドキュメントによれば、Chat Completion APIのパラメーターの一つであるfrequency_penaltyとpresence_penaltyを使うことでトークンの繰り返し実行のサンプリングの可能性を減らせます。ということなのですが、正直なんのことやら。こちらのQiitaの記事を拝見しても理解が進まなかったので、色々試してみました。
まず、frequency_penaltyから検証してみます。frequency_penaltyは-2.0から2.0の値で設定でき、正の値を指定するとトークン内での繰り返しの出現を抑えるようです。とりあえず思い切って2に指定してみます。
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const completion = await openai.chat.completions.create({
messages: [{"role": "system", "content": "あなたは優秀なアシスタントです"},
{"role": "user", "content": "天候の予測がなぜ難しいのか説明して"},
],
model: "gpt-3.5-turbo",
frequency_penalty: 2,
});
console.log(completion.choices[0].message.content);
}
main();出力結果は下記の通り。途中から中国語?のようになってしまいました。

次にfrequency_penaltyの値を-2.0にしてみます。壊れたスピーカーのような結果になってしまいましたが、正の値とは真逆の負の最大値なので同じトークンを最大限繰り返すのようなイメージでしょうか。

最後にfrequency_penaltyの値を0.5にした結果です。まともな感じの文章になりました。

続けて、presence_penaltyについても検証してみましょう。
最初に、presence_penaltyを2.0にしてみます。

次に、presence_penaltyを-2.0にしてみます。

最後に、presence_penaltyを0.5にしてみます。

presence_penaltyについては、frequency_penaltyほどの大きな違いは生まれませんでした。それはそのはず、presence_penaltyのレファレンスには、この値が大きくなればなるほど新しいトピックを提示する傾向が強くなるという記載がありました。今回はそもそも天候の予測についての説明を求めている(同一テーマ)なので、違いが生まれにくいのではないかと思いました。というわけで、presence_penaltyについて「砂漠に雨を降らせる方法をブレインストーミングして」というプロンプトに変更して試してみました。
最初に、presence_penaltyを2.0にしてみます。

次に、presence_penaltyを-2.0にしてみます。

最後に、presence_penaltyを0.5にしてみます。

比較してみると、presence_penaltyの値が正方向に大きければ大きいほど、まずブレストで提示される数が大きいことがわかります。また、説明についても、2.0は言い切ってますが、-2.0は「考えられます」のようなニュアンス、0.5ですと「かもしれません」のようなニュアンスになっています。
まとめると、presence_penaltyはトークンに対して新しいトピックを提示する傾向の調整を行うことができる一方、frequency_penaltyは同じトークンの繰り返しをどの程度許容または制限するかの調整を行うことができる、というイメージになるでしょうか。
例えば、ブレインストーミングであれば同じトピック戻らないようにpresence_penaltyを0.6〜1.2にして新しいトピックへの移行を促しつつ、frequency_penaltyは低めの値に設定し一部の繰り返しを許容して一貫性を保持するという調整方法が考えられそうです。一方で、教育的・説明的テキストの場合であればpresence_penaltyを0.1〜1.5にして議論の焦点は維持しつつ、frequency_penaltyは中程度の値に設定し重要な用語の過度な繰り返しを防ぐという調整方法が考えられそうです。
トークンログ確率
logprobsやtop_logprobsを使ってトークンログ確率を出力させることができます。logprobsやtop_logprobsについてはChatGPT API検証 logprobs top_logprobsを参照されるとわかりやすそうです。出力に対してモデルの信頼性の検証に使えるのではないかということですが、アプリケーション実装上は現時点ではあまり利用しなさそうなので割愛いたします。
以上で、今回の投稿は終了となります。いかがでしたでしょうか。
次回はFunction Callingについてめとめていければと考えています!